
Hadoop大数据平台组件搭建系列 6 —— Spark完全分布式组件配置
简介
本篇介绍Hadoop大数据平台组件中的Spark组件的搭建
使用软件版本信息:
scala-2.11.12.tgz(百度云提取码:byqz)
spark-2.4.4-bin-hadoop2.6.tgz(百度云提取码:9xad)
安装
安装Scala
解压scala安装包至目标目录,记得重命名,方便后续操作
[root@master1 ~]# tar -zxvf /opt/software/scala-2.11.12.tgz -C /usr/local/scr/ [root@master1 scr]# mv scala-2.11.12/ scala修改环境变量
powershell[root@master1 scr]# vi /etc/profile添加以下内容
powershell#.....scala..... export SCALA_HOME=/usr/local/scr/scala export PATH=$PATH:$SCALA_HOME/bin刷新环境变量
powershell[root@master1 scr]# source /etc/profile检查安装scala版本
powershell[root@master1 scr]# scala -version出现下图则安装scala成功

安装Spark完全分布式
解压spark安装包,并重命名,便于后续操作
powershell[root@master1 scr]# tar -zxvf /opt/software/spark-2.4.4-bin-hadoop2.6.tgz -C /usr/local/scr/ [root@master1 scr]# mv spark-2.4.4-bin-hadoop2.6/ spark修改环境变量
powershell[root@master1 scr]# vi /etc/profile添加以下内容
powershell#......spark..... export SPARK_HOME=/usr/local/scr/spark export PATH=$PATH:$SPARK_HOME/bin刷新环境变量
powershell[root@master1 scr]# source /etc/profile进入 conf 目录下,复制 spark-env.sh.template 改为 spark-env.sh,并修改内容
powershell[root@master1 conf]# cp spark-env.sh.template spark-env.sh [root@master1 conf]# vi spark-env.sh在最后添加以下内容:
powershellexport JAVA_HOME=/usr/local/src/jdk export SCALA_HOME=/usr/local/scr/scala export HADOOP_HOME=/usr/local/scr/hadoop export HADOOP_CONF=/usr/local/scr/hadoop/etc/hadoop export SPARK_MASTER_IP=192.168.200.1 export SPARK_MASTER_HOST=192.168.200.1 export SPARK_LOCAL_IP=192.168.200.1 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_CORES=2 export SPARK_HOME=/usr/local/scr/spark export SPARK_DIST_CLASSPATH=$(/usr/local/scr/hadoop/bin/hadoop classpath)修改slaves配置文件
复制 slaves.template 改为 slaves
powershell[root@master1 conf]# cp slaves.template slaves [root@master1 conf]# vi slaves删除最后一行的localhost,添加以下内容
powershellmaster1 master2 slave1 slave2将 scala、spark、环境变量文件 拷贝分发给master2、slave1、slave2节点
powershell#拷贝spark [root@master1 conf]# scp -r /usr/local/scr/spark/ master2:/usr/local/scr/ #拷贝scala [root@master1 conf]# scp -r /usr/local/scr/scala/ master2:/usr/local/scr/ #拷贝环境变量 [root@master1 conf]# scp -r /etc/profile master2:/etc/profile .... ....在每个拷贝分发的节点上,修改 spark-env.sh 中的 SPARK_LOCAL_IP,改为对应IP地址
在master1节点启动spark
powershell[root@master1 conf]# /usr/local/scr/spark/sbin/start-all.shjps查看
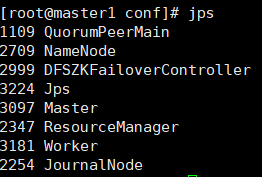
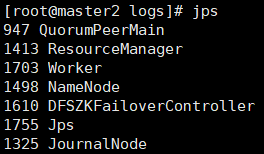
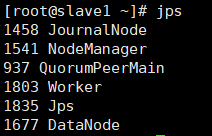
每个节点出现worker进程,切master1节点上有master节点,如下图
**master1节点**
**master2节点**
**slave1节点**
slave2节点

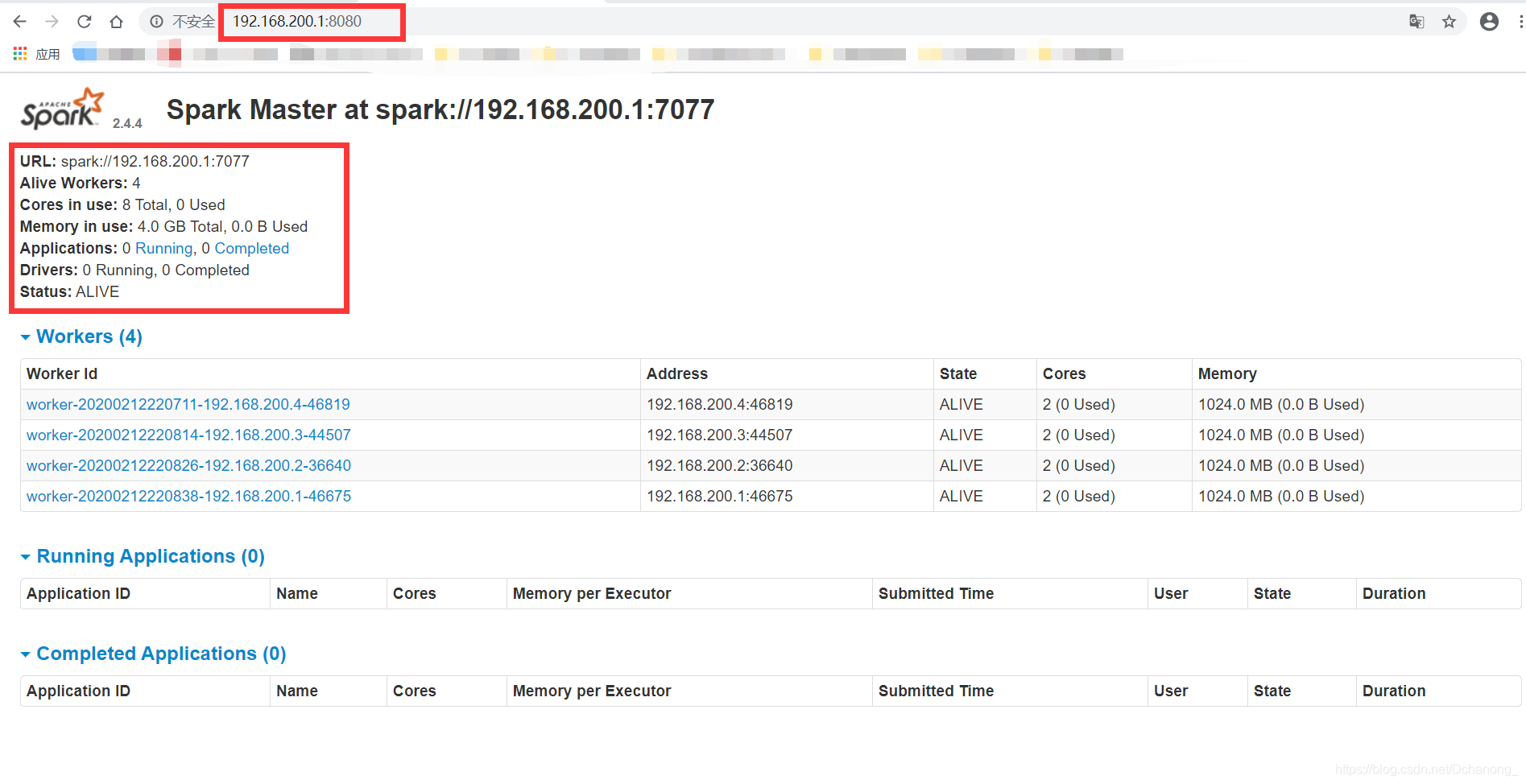
web端查看spark
master 端口号:==8080==
系列文章
Hadoop HA高可用+Zookeeper搭建 一站式解決方案!!!
Hadoop大数据平台组件搭建系列 —— Hadoop完全分布式搭建(基于CentOS7.4)史上最简单的Hadoop完全分布式搭建 一站式解决!!!
Hadoop大数据平台组件搭建系列 1—— Zookeeper组件配置
Hadoop大数据平台组件搭建系列 2 —— Sqoop组件配置
Hadoop大数据平台组件搭建系列 3 —— Hive组件配置
Hadoop大数据平台组件搭建系列 4 —— Kafka组件配置
Hadoop大数据平台组件搭建系列 5 —— MySQL组件配置(tar源码安装)